



Diffusion models exploded onto the world stage a mere two years ago. The technology had been around for a while, but it was only when we all experienced the revolution of AI image generation that it came into stark focus.
Suddenly everyone and their dog could create astounding works of art simply by typing a prompt into a text box.
But diffusion models are not just about art and image creation. The scientific world, music and even Hollywood, have started to to understand the benefits of this powerful AI technology.
How does it work?
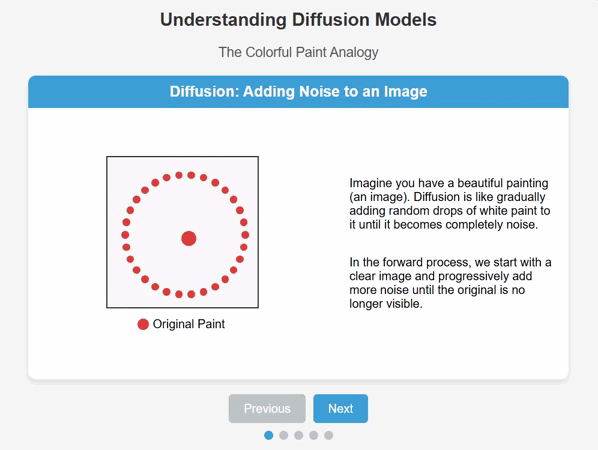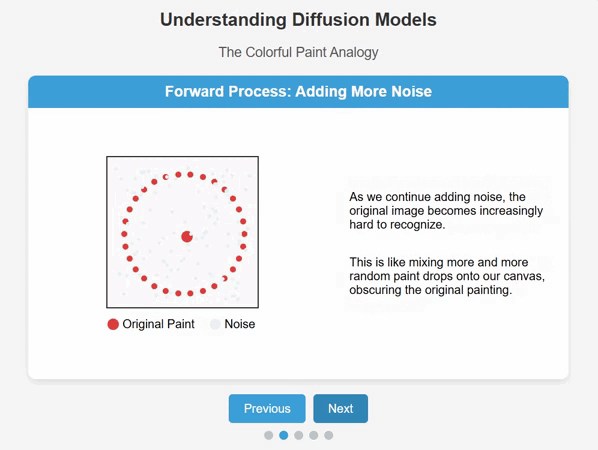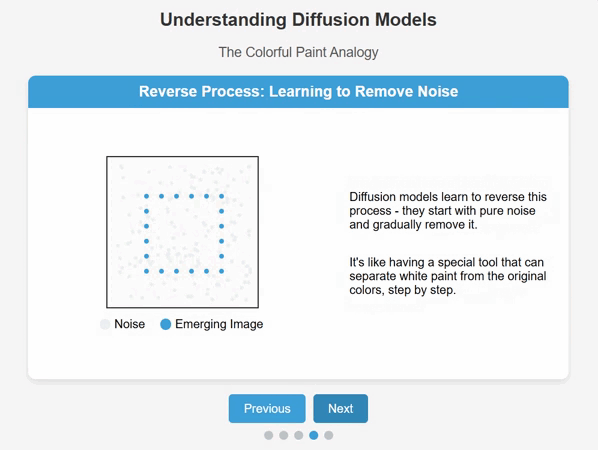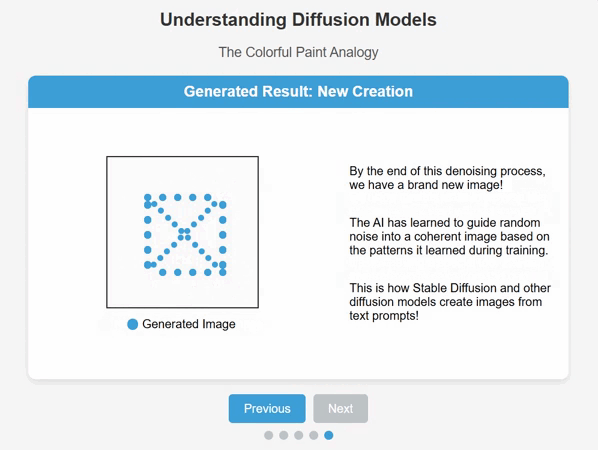
Diffusion works by adding noise to training data until it becomes completely unrecognizable, and then reversing the process to create novel data from the original learnings.
It’s rather like a sculptor ‘uncovering’ their vision by slowly chipping away at the stone wood or plaster in front of them.
The clever bit is teaching the AI model to understand how to recreate a new version of the original data by subtracting noise until the desired result comes into ‘focus’.
Diffusion is one of the hardest AI concepts to explain to the layperson. When people talk about AI stealing art or music, what they don’t realize is the diffusion models which deliver these miraculous results, are not acting directly on the original training data, but are using that data as a starting point from which to create something completely new and unique.
Give the model a picture of a black cat and from that point the model will learn how to recreate a similar image with infinite variations, simply through using this process of noise diffusion and reduction.

One of the key strengths of diffusion models is their ability to work without needing structured training data.
This makes them extremely versatile, as instead of relying on clearly labelled examples, a diffusion model learns how to recreate content by understanding how to denoise and restructure the original training data they were given.
Because noise can be infinitely complex, so too can the end result be incredibly complex. Hence their application not just in art, but also music, science and other areas which require complex AI processing.
Architects are today increasingly using diffusion models to visualize new building styles, while fashion designers can instantly play with new clothing concepts.
One of the most valuable areas for these models is in the field of medical research, where diffusion techniques are increasingly being used to speed up and enhance diagnostic imaging.
The ability to instantly recognize and identify patterns in complex images makes these models perfect for diagnosing otherwise hidden or obscure medical conditions.
The downside of this kind of power is the need for increasingly sophisticated and powerful computers to effect the denoising process.
Low-powered computers inevitably result in unacceptably slower generation times.
Diffusion models are also very reliant on high-quality training data input, very much a case of garbage in, garbage out. There is also the question of input data bias, which can lead to aberrant results unless the model is trained properly over time.
This type of generative AI is now on the cusp of delivering AI video which is almost identical to human generated content.
However deepfake videos and other malevolent content are a growing problem on the internet, as is copyright abuse and synthetically generated content which is designed to aid criminal activity in a wide range of fields.
Despite these challenges, diffusion models are going to play an increasingly important role in our modern lives. The creative and functional advantages of having this kind of AI assistance on tap is proving to be a genuine revolution in almost every area we can think of.


{kind=link}